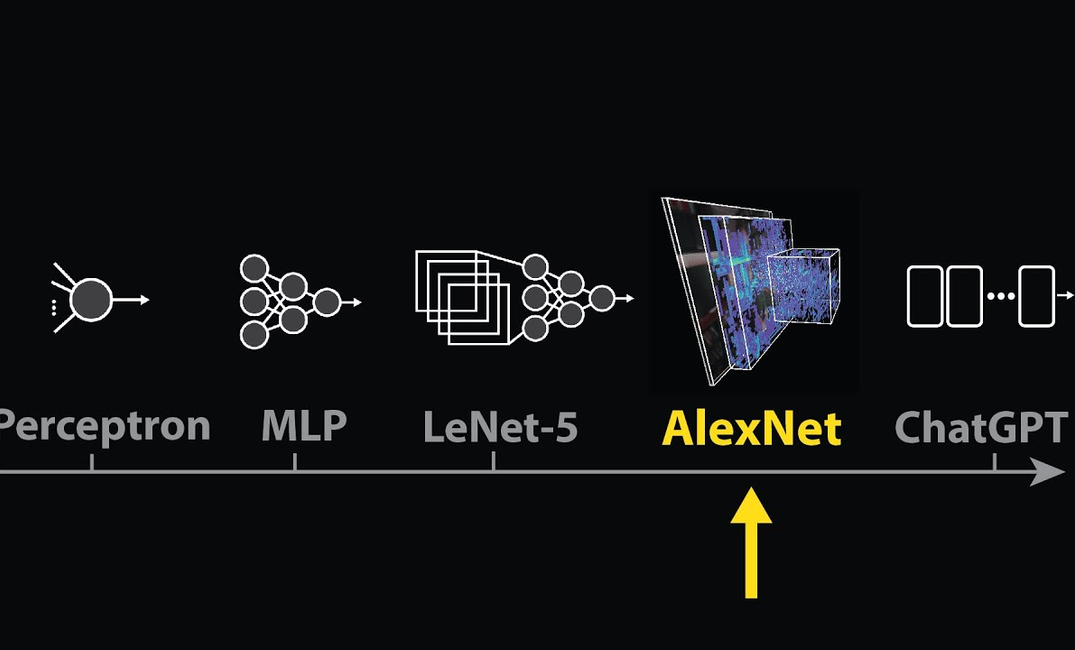
The video explores how AI models like Alexnet and ChatGPT manage to understand and interact with the world using high-dimensional Embedding spaces. It highlights the historical significance of Alexnet, published in 2012, which astonished the computer vision community by showing remarkable performance by scaling an older AI concept. This development paved the way for OpenAI's creation of ChatGPT, utilizing AI's ability to process data in layers of compute blocks called transformers.
Delving into the mechanisms, the video explains how ChatGPT formulates responses using repeated Matrix transformations. It outlines how inputs, whether images in Alexnet or words in ChatGPT, go through layered processing to yield desired outputs. This sequential computation unlocks capabilities in AI to perform tasks like image classification in Alexnet and generating text in ChatGPT – all achieved through learned data patterns and Activation maps that give insight into AI's understanding level.
Main takeaways from the video:
Please remember to turn on the CC button to view the subtitles.
Key Vocabularies and Common Phrases:
1. Embedding [ɛmˈbɛdɪŋ] - (n.) The process of representing data in a high-dimensional space to find patterns or relations.
It gives us a glimpse into the High dimensional Embedding spaces modern AI models use to organize and make sense of the world.
2. Transformational [trænsˈfɔːrmeɪʃənəl] - (adj.) Relating to a marked change or transformation in form or appearance.
Each transformer performs a set of fixed Matrix operations on an input Matrix of data.
3. Vector [ˈvɛktər] - (n.) A quantity having direction as well as magnitude, especially in determining the position of one point in space relative to another.
All of these vectors together into a Matrix.
4. Activation [ˌæk.tɪˈveɪ.ʃən] - (n.) The action of making something active or operative.
The Activation maps show us which parts of an image, if any, match a given Kernel.
5. Matrix [ˈmeɪtrɪks] - (n.) A rectangular array of numbers or other entities, where relations or calculations are performed upon.
This Matrix is then passed into the first transformer block.
6. Perceptron [pəˈsɛp.trɒn] - (n.) An algorithm for supervised learning of binary classifiers, used in an AI neural network.
The Perceptron is a Learning algorithm and physical machine from the 1950s.
7. Convolutional [ˌkɒnvəˈluːʃənəl] - (adj.) Referring to a mathematical operation on two functions producing a third.
The first five layers of Alexnet are all Convolutional blocks.
8. Neural Networks [ˈn(j)ʊərəl ˈnɛtwɜ:rks] - (n.) Computing systems inspired by biological neural networks, forming the basis of AI models.
Despite the intermittent successes of artificial neural networks over the years.
9. Parameters [pəˈræmɪtərz] - (n.) Numbers that characterize some systems’ function or behavior.
Alexnet increased this 1000 fold to around 60 million parameters.
10. Algorithm [ˈælɡəˌrɪðəm] - (n.) A procedure or formula for solving a problem.
Despite the intermittent successes of artificial neural networks over the years.
Unveiling The Hidden Mechanisms Behind AI Intelligence Wonders
This is an Activation atlas. It gives us a glimpse into the High dimensional Embedding spaces modern AI models use to organize and make sense of the world. The first model to really see the world like this, Alexnet, was published in 2012 in an eight page paper that shocked the computer vision community by showing that an old AI idea would work unbelievably well when scaled.
The paper's second author Ilya Sutzkever would go on to co-found OpenAI, where he and the OpenAI team would massively scale up this idea again to create ChatGPT. If you look under the hood of ChatGPT, you won’t find any obvious signs of intelligence. Instead, you'll find layer after layer of compute blocks called transformers. This is what the T in GPT stands for.
Each transformer performs a set of fixed Matrix operations on an input Matrix of data, and typically returns an output Matrix of the same size to figure out what it's going to say next. ChatGPT breaks apart what you ask it into words and word fragments, maps each of these to a vector, and stacks all of these vectors together into a Matrix. This Matrix is then passed into the first transformer block, which returns a new Matrix of the same size.
This operation is then repeated again and again 96 times in ChatGPT 3.5 and reportedly 120 times in ChatGPT four. Now here's the absurd part with a few caveats. The next word or word fragment ChatGPT says back to you is literally just the last column of its final output, and Matrix mapped from a vector back to text to formulate a full response.
This new word or word fragment is appended to the end of the original output, and this new, slightly longer text is fed back into the input of ChatGPT. This process is repeated again and again, with one new column added to the input Matrix each time until the models return a special stop word fragment. And that is it.
Where is the intelligence? How is it that these 100 or so blocks of dumb compute are able to write essays, translate language, summarize books, solve math problems, explain complex concepts, or even write the next line of this script? The answer lies in the vast amounts of data these models are trained on.
The AlexNet paper is significant because it marks the first time we really see layers of compute blocks like this. An AI tipping point towards high performance and scale and away from explainability. While ChatGPT is trained to predict the next word fragment given some text, AlexNet is trained to predict a label given an image.
Artificial Intelligence, Technology, Innovation, Alexnet, ChatGPT, Deep Learning